urllib3 seems to be a long-abandoned project on PyPI. However, it
has some features (like re-using connections, aka HTTP Keep-Alive) that
are not present in the Python 2 version of urllib and urllib2.
Another package that provides HTTP Keep-Alive is httplib2.
Benchmark results on a single host
Keep-Alive can significantly speed up your scraper or API client if you’re
connecting to a single host, or a small set of hosts. This example shows the
times spent downloading random pages from a single host, using both urllib2
and urllib3:
urllib-benchmark-results.png
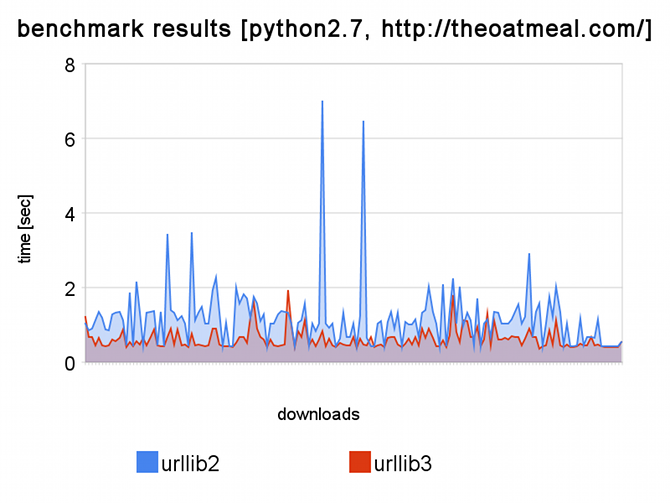 urllib2 vs. urllib3 benchmark results
urllib2 vs. urllib3 benchmark results
The benchmark script
Here’s a script that will benchmark urllib2 and urllib3 for the domain
theoatmeal.con, and write out the results to a CSV files (easy to importy to
Google Docs Spreadsheet and generate a nice chart).
If you run it, it will also prent the result summary, something like this:
Starting urllib2/urllib3 benchmark...
* crawling: https://theoatmeal.com/
* crawling: https://theoatmeal.com/comics/party_gorilla
* crawling: https://theoatmeal.com/comics/slinky
* crawling: https://theoatmeal.com/blog/floss
...
Finishing benchmark, writing results to file `results.cvs`
Total times:
* urllib2: 183.593553543
* urllib3: 95.9748189449
As you can see, urllib3 appears to be twice as fast as urllib2.